Method
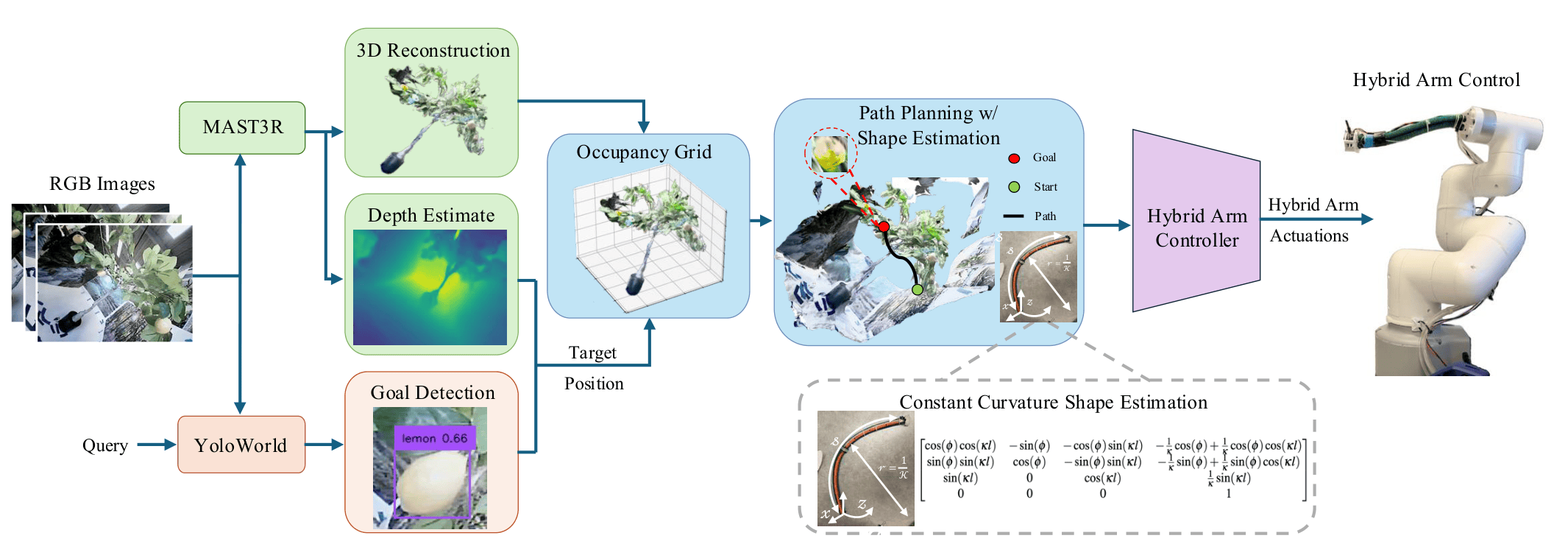
HyReach is built on a hybrid platform: a standard 6-DoF industrial robotic arm with a tri-chambered bending soft continuum arm (SCA) at its distal end. Our framework couples three stages - perception, shape-aware planning, and learning-based control - enabling safe, goal-directed reaching in visually occluded, obstacle-rich scenes.
Stage 1 - Perception
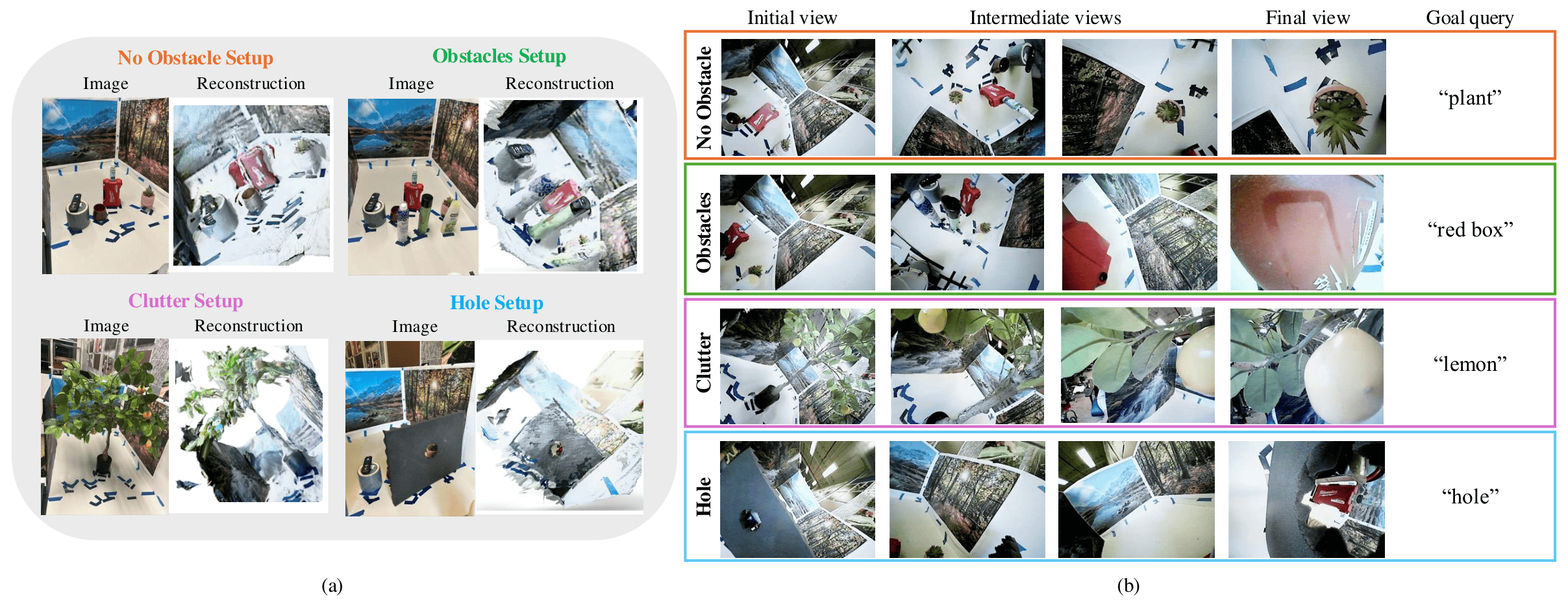
A monocular tip-mounted camera collects multi-view RGB images during an exploratory sweep. Mast3r reconstructs metric-scale 3D geometry, while YOLO-World localizes goal objects via natural-language queries, no fixed object categories, no depth sensor required.
Stage 2 - Shape-Aware Planning
A modified RRT* planner evaluates candidate trajectories against a voxel occupancy grid, checking collisions along the entire hybrid backbone. A Constant Curvature model estimates the SCA's shape online, enforcing strict collision-free motion for the rigid segment while allowing bounded contact for the compliant soft segment.
Stage 3 - Learning-Based Control
A neural controller maps current and goal poses to actuator commands for both rigid and soft segments. Trained once on a target-pose dataset, it generalizes across environments without retraining, accurately executing planned waypoints in real time.